AI Cost & Reliability Engineering
Fix wrong answers, cost spikes, and release regressions in production LLM systems
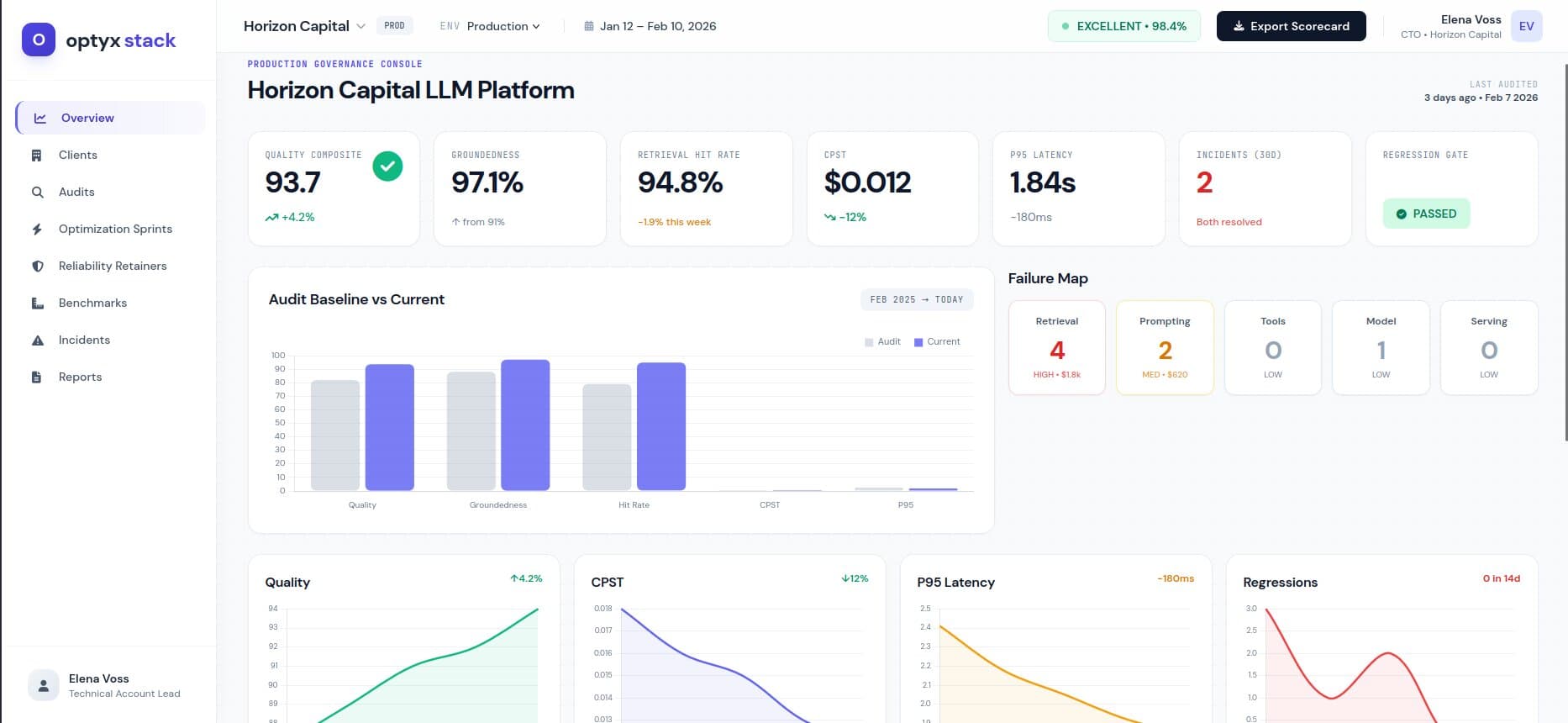
For teams running RAG, copilots, or agents in production, OptyxStack audits the system, isolates failure modes, ships targeted fixes, and gives leadership before/after evidence.
Signal 01
Baseline before opinions
Leadership gets one scorecard before the team debates prompts, models, vendors, or retrievers.
Signal 02
Fixes ranked by ROI
Recommendations are sequenced by quality impact, cost effect, engineering effort, and rollout risk.
Signal 03
Release confidence after
Regression gates turn one-off improvements into a repeatable release process.
Why enterprise teams get stuck
We understand your pain
Without evals and monitoring, you can't separate failures in retrieval, prompting, tools, or the model. We run a second-opinion audit, quantify the gap, and produce a decision-ready recovery plan.
Common failure surfaces
The problem is usually not “the model”
Retrieval
Recall benchmark + rerank tuning
Answerable queries still miss the right evidence.
Prompting
Prompt compression + routing policy
Prompt bloat increases spend without improving quality.
Tools
Trace review + fallback design
Tool calls succeed technically but fail user intent.
Model
Cohort scoring + policy updates
Model selection drifts away from cost-quality target.
4
Failure layers isolated: retrieval, prompt, tools, model
$3.8k
Fixed-scope audit starting point
5-14
Working days to baseline and decision memo
24h
Initial response window
Scope is transparent up front: audit first, sprint only when the baseline supports it, governance only when your team needs ongoing control.
Buyers do not need more slogans. They need concrete artifacts, clear scope, and an honest view of how delivery works.
Sample deliverable
Review the audit output format before you buy.
OpenAnonymized case studies
See the baseline, fixes, and measurable deltas.
OpenTransparent pricing
Understand scope, timelines, and where each offer fits.
OpenPrivacy and handling
NDA-friendly, redaction-ready, least-privilege workflows.
OpenWhat buyers usually need before they say yes
We make the diligence path explicit: see the deliverables, compare scope, review anonymized write-ups, then decide whether to start with the audit.
How it works
Start with an AI Production Audit. If the data supports action, move into a focused Optimization Sprint. Keep governance only when ongoing drift risk justifies it.
AI Production Audit
Baseline the system: quality score, cost per conversation, retrieval hit rate, latency, and failure modes.
Deliverables
- Baseline metrics
- Failure analysis
- ROI roadmap
Optimization Sprint (4–6 weeks)
Focus on the highest-value fixes. Ship PRs and verify before/after changes across quality, cost, and reliability.
Deliverables
- Production PRs
- Before/after benchmarks
- Eval harness
Reliability Retainer
Keep evals, monitoring, regression tests, tuning, and incident triage active after the main fixes land.
Deliverables
- Monitoring dashboards
- Regression gates
- Incident triage
Quality, cost, reliability—measured
We baseline the system first, then measure the deltas after fixes. You keep everything: code, evals, dashboards, runbooks.
Model-agnostic. Works with OpenAI / Anthropic / Gemini / Bedrock / Azure OpenAI + your vector DB.
Make answers grounded
MeasuredGroundedness score, citation checks, human review where needed, and RAG retrieval/reranking fixes.
Reduce cost per conversation
BenchmarkedBaseline and post-fix cost per conversation using routing, caching, context trimming, and retry control.
Prevent regressions
ControlledChange control, regression gates, release checks, and drift signals for prompts, models, tools, and retrieval.
What you get
We ship PRs—not decks.
- Eval harness + golden set template
- Dashboard: cost/latency/quality + error taxonomy
- Root-cause analysis + ROI roadmap
- PRs shipped (prompt/RAG/routing/caching/serving)
- Regression gates in CI
- Runbook + handoff session
Sample deliverables. Actual format tailored to your stack.
Enterprise use cases across finance, legal, healthcare, support
Best fit: enterprises running LLMs/RAG/agents in production with accuracy, reliability, cost, or drift pain.
Good fit
Recommended
- Finance, legal, healthcare: RAG/copilot with grounded answers & compliance
- Support: chatbot wrong answers—recovery + eval gates
- Vendor-built systems needing second-opinion audit
- Teams willing to measure outcomes and ship fixes
Not a fit
No action needed
- AI strategy decks or model training from scratch
- Tool setup only (no system diagnosis)
- No production usage yet
- Not willing to measure outcomes
Benchmark examples: accuracy, reliability, cost per successful task
The audit format is simple: baseline the system, ship targeted fixes, verify the change with benchmarks.
Benchmark style
Representative before/after signals, not promises or vanity metrics.
What changes
Quality, cost, and release confidence move together or the fix is incomplete.
What stays
Artifacts, evals, dashboards, and operating logic remain with your team.
Audit snapshot
Support copilot (B2B SaaS)
Groundedness
68% -> 91%
Escalation rate
18% -> 7%
Retrieval hit rate
61% -> 88%
Context: RAG wrong answers despite docs containing the info.
Constraint: Retrieval failure modes, no golden set.
Fix shipped: Golden set + eval harness, retrieval/rerank fixes, verification for high-risk answers.
Representative audit snapshot format. Actual baselines are measured from your system.
Audit snapshot
Internal assistant (Enterprise)
Cost / conversation
$0.042 -> $0.021
Pass rate
72% -> 89%
Release risk
manual -> gated
Context: Token spend spiked after prompt changes; quality regressed.
Constraint: Prompt bloat, no caching, no regression gates.
Fix shipped: Context trimming + caching, routing policy by cost/quality, regression gates in CI.
Representative audit snapshot format. Actual baselines are measured from your system.
More case studies
AI Production Audit: Why a Support Copilot Was Wrong, Slow, and Expensive
A support copilot was drawing complaints from every direction: wrong answers, slow responses, and rising spend. In five working days, we turned anecdotal pain into a measured baseline, isolated the dominant failure modes, and delivered a fix order the team could finally trust.
View detailsHardening a Production RAG System Against Prompt Injection (Without Breaking UX)
A production RAG assistant blended untrusted user text, retrieved content, and tool capabilities inside one decision path. We rebuilt trust boundaries across prompt, retrieval, tool, and output layers with immutable policy separation, capability-scoped tools, citation-gated answers, isolated execution, and attack-suite validation. Representative injection and exfiltration paths were blocked without forcing normal users into brittle refusals.
View detailsPrivacy-Safe LLM Observability: Debuggable Logs Without Storing PII
Logging for eval and debug meant storing PII—compliance blocked it. We built a redaction pipeline, hashing, sampling, access controls, retention policy, and synthetic replay sets for eval. Result: debuggable logs, no PII in storage, compliance review passed.
View detailsFrequently asked questions
Audit scope, RAG failures, hallucination measurement, vendor systems, and data access. We work with least-privilege access and can operate under NDA on redacted data.
What does the AI Production Audit include?
A fixed-scope baseline of quality, cost, latency, retrieval behavior, and regression risk. The handoff includes findings, a failure map, prioritized fixes, and a decision memo your engineering and leadership teams can use.
Why is our RAG not working in production?
Usually it is retrieval quality, chunking, embedding mismatch, ranking, missing evals, or production drift. We isolate the failure mode before recommending prompt, retrieval, model, or tooling changes.
How do you measure hallucination rate?
We define a groundedness and correctness rubric, build or improve a golden set, then run human review or LLM-as-judge where appropriate. The important part is repeatability: the same checks should catch future regressions.
Can you audit a vendor-built AI system?
Yes. We run second-opinion audits on vendor-built systems: baseline performance, identify root causes, and provide a recovery plan. If your team controls the code or configuration, we can also scope PR-level fixes.
Do you need production access or customer data?
No. We can operate on staging, redacted datasets, or sample conversations. Read-only logs and metrics are typically sufficient—and no customer data is used to train models.
What happens after the audit?
If the baseline shows clear ROI, we can scope an Optimization Sprint. If the fix is small, your team can use the roadmap directly. If ongoing drift is the main risk, a retainer may make sense.
Fixed-scope entry point
Ready to baseline your system?
Fixed-scope audit. Response within 24 hours.
Audit scope
1-2 weeks to baseline the system
Decision memo with prioritized fixes
Optional sprint if the data supports it